I know you love them, and I know you were waiting with baited breath, so it’s time once again for the year in review of my game buying!
Overall the year was down in spending, but up in aquisitions. Here’s the beloved plots, in a shiny new format to silence the haters…
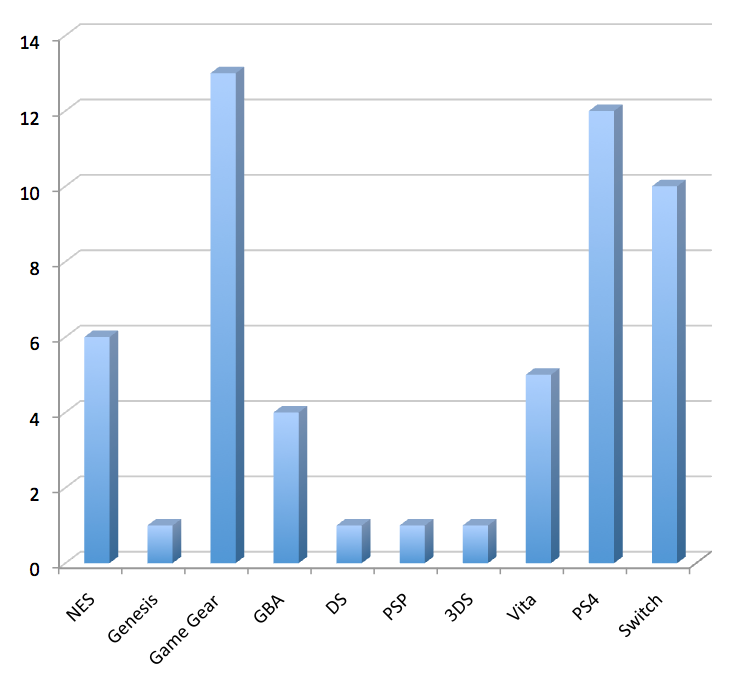
First, by total games purchased:
And secondly, by total dollars spent:
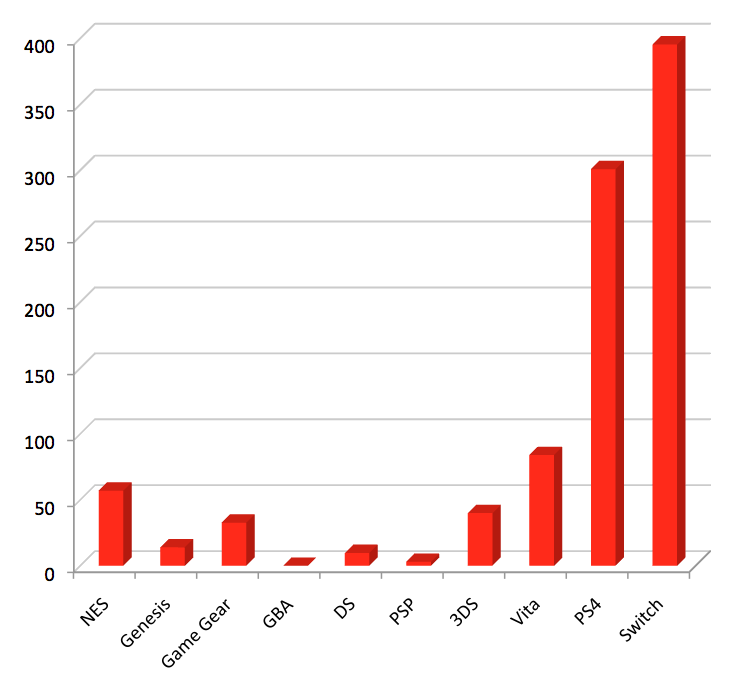
Some interesting information here. For instance, who would have thought I would have bought more games for the (Sega) Game Gear than any other console in 2018?!? What about the Genesis, or NES or even PSP? And from barely being on the charts last year now the Switch is #1 in dollars spent? Let’s unpack these a bit…
Firstly there was a definite retro trend in my buying in 2018. Of the $936 I spent on games this year, over $200 was for dead systems. And since I’m not buying the pricey games (I own most of them already!) this translated to a lot of purchases – over 30 – for ‘dead’ systems. Much of this was boosted by a mega-haul of 12 Game Gear games picked up in a Scottish CSX for under US$20, but I also wandered out of the occasional retro game store over here with NES and Genesis games this year and even found (for only $3!) a sealed copy of a UK PSP game at – of all places – a NY City street vendor stall!
Secondly the handheld market collapsed. In 2017 I spent almost $750 on 3DS and Vita games alone. In 2018, I bought 80% fewer games for these systems and spent under $120. It’s entirely possible that in 2019 I buy nothing for either system. This is melancholic, since I have always been a big fan and booster of handhelds and don’t personally feel the Switch is the replacement. A good thing therefore that I have approximately 875 handheld games in my collection to keep playing for ever 🙂
Thirdly the Switch roared into first place, backed by an amazing lineup of games, a beautiful piece of hardward and a very promising future. There’s a lot to love about this system, not the least of which is that it is cartridge based, but for me the migration to the Switch of many iconic Japanese developers bodes very well for the future in terms of the sorts of games I like.
Deciding on my favourites in 2018 was very difficult because there were so many great games I played. I considered the copout route of doing one per system as well but even that was hard. So I’ll do the cop-copout route and talk about franchises, and in 2018 it boiled down to two for me:
Monster Hunter Series


Amazingly 2018 saw two MH series games released. The first and most important was Monster Hunter World for PS4 (first pic) which came out early in the year and took over my life for weeks. It’s a magnificent tour-de-force of a game, absolutely worthy of the many accolades it has earned and I eagerly await the expansion due next year.
In the middle of the year Nintendo finally got around to translating the Switch version of Monster Hunter XX (second pic) and once I had uploaded my save file (from the 3DS prequel) and set foot into the new G-Rank content I was giddy with joy. After the changes of MH World it was like visiting an old friend and coupled with some amazing new opponents – the final mantis boss in particular – this may have been the most fun I had ever had playing MH. Alas, I fear World had stolen the fanbase though, and online play was barren. Perhaps this was because I was at the very edge of progression (I broke the HR barrier I think the day after I got the game) and there were very few players at my level? Either way I beat all the content mostly solo and once Nintendo required payment for online play put the game aside to play everything else.
Xenoblade Chronicles 2 Series
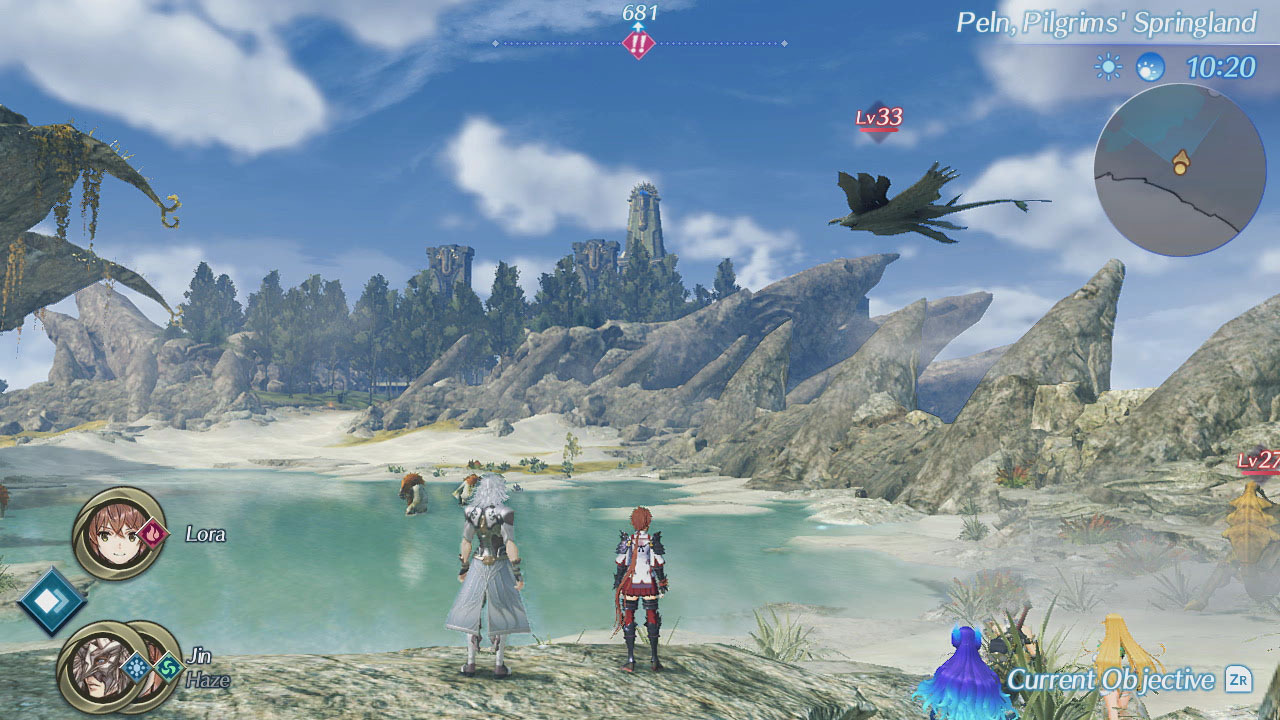
I played the third and fourth Xenoblade Chronicles games in 2018, both on Switch. The first (Xenoblade Chronicles 2) was a 150-hour massive open world RPG with incredible gameplay, amazing graphics and finely detailed ‘systems’ that would dazzle a statistician. Just my sort of game in other words. But did it surpass Xenoblade Chronicles 1 or X? Hard to say: it was at least as good and maybe better. The series is remarkable for it’s consistency though, and every game is well worth playing.
Later in the year a ‘DLC’ was released that was basically an entirely new game. Titled Torna The Golden Country this reused a modified version of the XC2 engine to tell a story set in the same world only many thousands of years before. And this game was astonishing, to the point of perhaps being the single best game experience I had in 2018. Highly recommended (although you’ll need XC2 to play it…)
So once again Xeno and MH games bubble to the top, but I have to add that these were simply the brighest sparks in a year full of excellent games. From the Vita (Danganronpa), 3DS (Etrian Odyssey 5), PS4 (Hollow Knight) to Switch (Super Mario Odyssey) there were countless other games that could have made the top list any other year.
So what does 2019 hold? I expect the trend of less spending will continue, especially as I am becoming increasingly likely to delve into my collection and replay games I already own. However the Switch is the big unknown. I’ve already purchased two retro collections for the system (Namco and SNK), two more are on the horizon (Capcom and Taito) and if the trend continues and the old Japanese arcade companies release more and more of their content for the Switch then who knows how much better the console will get? In another year you can find out… 🙂
















